deepseek是一款备受欢迎的人工智能平台,专注于大语言模型(llms)的研发与应用。相较于云端服务,本地部署deepseek不仅可以提升离线可用性,还能保障数据的私密性。本文将详细介绍如何在本地部署deepseek,帮助目标用户全面了解这一过程。
一、部署前准备
在进行deepseek本地部署之前,用户需要做好以下准备工作:
1. 硬件要求:本地部署对硬件要求较高,尤其是高参数模型需要强大的gpu及充足内存。建议使用高性能的nvidia显卡,并确保安装了正确版本的cuda和cudnn。对于amd显卡用户,可能需要安装特定版本的驱动并配合特定软件使用。
2. 操作系统:linux是推荐的操作系统,但windows系统也支持。用户需要根据自己的系统选择相应的安装包。
3. python环境:确保python版本在3.7及以上,并准备好一个干净的python虚拟环境,以避免依赖冲突。
4. 依赖包:安装pytorch(版本>=1.7.1)、transformers(版本>=4.0)等依赖库。其他相关的库如numpy、pandas、scikit-learn等也建议安装。
二、核心部署流程
以下是deepseek本地部署的核心步骤:
1. 安装ollama框架:
* 访问ollama官网,下载对应系统版本的安装包。windows用户建议安装到c盘。
* 双击运行安装包,按照提示完成安装。

* 验证安装是否成功。打开命令行工具(如cmd),执行`ollama-v`命令,如果显示ollama版本号,则说明安装成功。
2. 下载并部署deepseek模型:
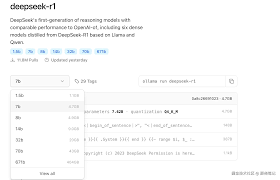
* 访问deepseek的模型库页面,根据自己的电脑配置选择合适的参数版本。例如,可以选择deepseek-r1的7b或8b版本。
* 在命令行中执行相应的命令自动下载并部署模型。例如,对于deepseek-r1的7b版本,可以执行`ollama run deepseek-r1:7b`命令。系统会自动下载模型文件,下载完成后即可进入交互模式。
3. 测试deepseek模型交互:
* 在命令行窗口中执行相应的命令进入交互界面。例如,对于deepseek-r1的8b版本,可以执行`ollama run deepseek-r1:8b`命令。
* 在交互界面中,用户可以输入问题,并等待模型给出回答。如果交互过程中响应较慢,可以多按几次回车,耐心等待下载完成和加载模型。
三、优化交互体验
为了优化deepseek的交互体验,用户可以考虑使用以下方案:
1. 使用ui工具:命令行交互虽然方便,但可能不够直观。用户可以使用一些ui工具来更方便地与deepseek进行交互。例如,可以使用chatbox等ai聊天工具,将deepseek模型配置到工具中,即可在界面上与模型进行聊天交互。
2. 安装open webui:open webui是一个功能强大的web界面,可以让用户通过网页端与deepseek模型进行交互。用户可以使用docker安装open webui,并按照提示完成配置。配置完成后,即可在web界面上与deepseek模型进行对话。
四、注意事项
在本地部署deepseek时,用户需要注意以下事项:
1. 依赖问题:确保所有依赖库都正确安装。如果遇到依赖问题,可以尝试升级pip或使用`--no-cache-dir`选项重新安装依赖库。
2. 模型下载问题:如果下载模型失败,请检查网络连接或尝试手动下载模型并指定路径。
3. gpu加速问题:如果使用gpu进行加速,请确保安装了正确版本的cuda和cudnn,并正确配置了pytorch以支持cuda。

通过本文的介绍,相信目标用户已经对deepseek的本地部署有了更全面的了解。本地部署deepseek不仅可以提升离线可用性,还能保障数据的私密性。希望本文能帮助用户顺利完成deepseek的本地部署,并享受更加便捷、安全的ai服务。